观察者模式
Zookeeper实际是观察者模式负责存储管理数据,接收观察者的注册,一旦数据发生变化,Zookeeper负责通知对应的观察者
Zookeeper=文件系统+通知系统
Zookeeper特点
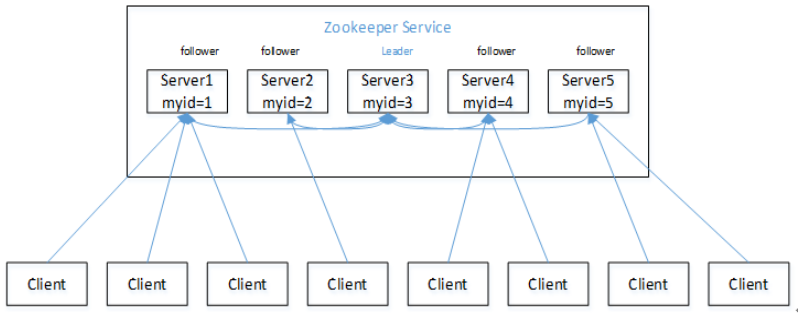
1,一个领导者(Leader)多个跟随着(Follower)
2,集群中只要有半数以上节点存活,Zookeeper集群就能正常服务
3,全局数据一致,每个Server都保存一个相同的副本,Client无论连接到那个Server数据都一致
4,更新请求顺序执行,来自同一个Client的更新请求按其发送顺序,依次执行
5,数据更新原子性
6,近实时性,在一定范围内,Client都能获取到最新数据
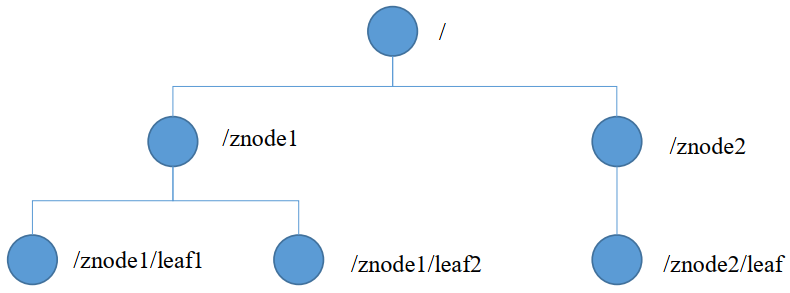
数据结构
通过树节点存储,每个节点叫一个ZNode,默认每个ZNode可以存储1M数据,每个ZNode可以通过路径唯一确定
应用
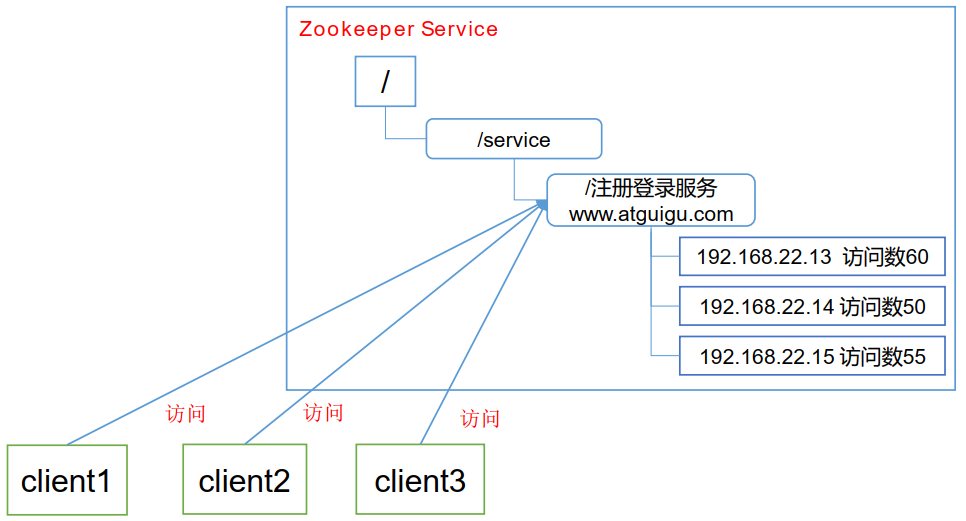
1,统一命名管理(一个域名对应多个IP地址)
2,统一配置更新(将配置信息存储到一个ZNode上,多个客服端观察,一旦改变Zookeeper会通知各个客服端更新)
3,统一集群管理(实时监控节点状态变换,将节点信息写入ZNode,监听该ZNode实时获取其变化)
4,服务动态上下线(服务启动会注册到对于的根节点下,下线会取消注册,服务消费者可以观察该节点,动态获取服务状态)
5,软负载均衡(图同1,会在每个IP下记录访问次数,让访问次数最少的去处理新的请求)
客服端命令(不存在的命令会直接打印所有支持的命令相当于Help)
注意监听前都会普通调用一次(主要是减小服务器压力,需要时才监听)
ls path [watch]:按路径查看指定节点的包含节点 watch监听包含节点是否变化(非阻塞,调用一次只监听一次)
ls2 path [watch]:查看指定路径下更详细的信息 watch使用同上
create path value(必须有value否则创建失败) 创建普通节点 -s(创建节点若已经存在添加序号,默认创建若存在会报错) -e(创建临时节点)
get path [watch]:获取指定节点value watch非阻塞监听节点值变化,调用一次只监听一次
set path value:设置节点值
stat path:查看节点状态
delete path:删除单个节点(不能有子节点)
rmr path:递归删除节点
quit:退出关闭客服端
配置文件(/conf/zoo.cfg)
# 心跳时间(毫秒),每tickTime发送一次心跳,会默认设置session超时时间为两倍心跳时间
tickTime=2000
# Follower与Leader初始连接时能容忍的心跳数,超出视为连接失败
initLimit=10
# Follower与Leader同步通信的最大心跳数,若超出该时间,Leader会认为Follower死掉,从服务列表把它删除
syncLimit=5
# 用于保存持久化文件数据
dataDir=../data
# 服务端口
clientPort=2181
选举机制
流程:(每台机器启动先给自己投票,未果投票给Id大的,超过半数的投票才算数,因此必须有半数或以上的启动集群才能正常工作,这里举例有5台依次启动)
第一台,投票给自己并发送投票消息,因为其他机器未启动,它一直处于选举状态
第二台,依旧投票给自己,并与第一台交换信息,因为投票数未超过半数,投票无效
第三台,给自己投票,此时超出了半数,票数相同(会重投给Id大的),第三台编号大胜出成为Leader,其他成为Follower
第四台,给自己投票,虽然编号大,但是已经有Leader成为Follower,后面的类似成为Follower
节点类型
持久:客服端创建的节点不会在断开连接后删除
短暂:客服端创建的节点会在断开连接后自动删除
持久顺序:类似持久不过名称会追加一个父节点维护的自增数字
短暂顺序:类似短暂不过名称会追加一个父节点维护的自增数字
关于顺序的说明:创建ZNode时会对其设置顺序标识,在ZNode名称后附加一个顺序号,顺序号是一个单调递增的计数器,由父类维护
顺序号可以用于推断事件发生的顺序
节点详细信息解释
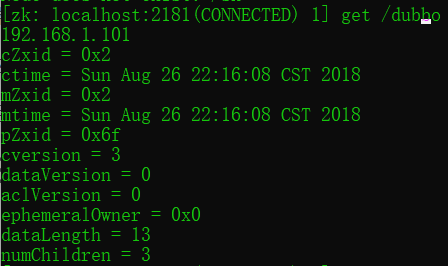
cZxid:事务ID,记录修改次序,每次修改都会有唯一的cZxid
ctime:创建时间(毫秒数)
mZxid:最后更新的事务Id
mtime:最后修改时间(毫秒数)
pZxid:最后更新的子节点
cversion:子节点变换号,记录子节点修改次数
dataVersion:数据变换号
aclVersion:访问控制列表的变换号
ephemeralOwner:临时节点,这个节点的session Id,不是临时节点,该值为0
dataLength:数据的长度
numChildren:子节点的数量
Zookeeper监听器原理

客服端会创建两个线程(connect负责网络连接,listener负责监听)
Zookeeper会把监听请求注册到监听器列表,一旦发生改变,Zookeeper会把这个消息发送给Listener线程
Listener线程内部调用process方法,对改变进行处理
Zookeeper写数据
1,Client写数据向Server1发送写请求
2,若该Server1不是Leader,Server1会把写请求转发给Leader,Leader负责把写请求广播给所有Server
3,Server写成功后会通知Leader,若超过半数的写数据成功,就认为写数据成功了,Leader最后再告诉该Server1写数据成功
4,该Server1进一步通知Client数据写成功
代码操控
依赖
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.10</version>
</dependency>
创建客服端
// 参数 连接地址 超时时间 监听事件
ZooKeeper keeper = new ZooKeeper("127.0.0.1:2181", 2000, watchedEvent -> {});
创建节点
// 创建节点 路径 值
String res = keeper.create("/sk", "HelloWorld".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);//创建模式
监听变换(同样只生效一次)
//获取子节点并指定监听 可以使用布尔值表示是否监听这样监听事件会触发创建ZooKeeper指定的监听器
List<String> list = keeper.getChildren("/", true);
// 若这样直接指定 触发这个,不再触发创建ZooKeeper时指定的
List<String> list = keeper.getChildren("/", System.out::println);
判断指定路径是否存在
// 判断指定路径是否存在 也可以监听 若存在返回其状态 不存在返回null
Stat exists = keeper.exists("/2233", false);
获取指定路径下的数据
byte[] data=zooKeeper.getData(baseNode + "/" + nodeName, false, null);//可以直接通过new String(data)转换为字符串
ZooKeeper的部署方式,集群角色,集群最少几台机器
1,单机模式,集群模式
2,角色有:Leader和Follower
3,集群最少3台
服务器角色
Leader
(1)事务请求的唯一调度和处理者,保证集群事务处理的顺序性
(2)集群内部各服务的调度者
Follower
(1)处理客户端的非事务请求,转发事务请求给 Leader 服务器
(2)参与事务请求 Proposal 的投票
(3)参与 Leader 选举投票
Observer
(1)3.0 版本以后引入的一个服务器角色,在不影响集群事务处理能力的基础上提升集群的非事务处理能力
(2)处理客户端的非事务请求,转发事务请求给 Leader 服务器
(3)不参与任何形式的投票




